Configuration Management in Behavox: Part 3 - CCMS


Hi, it's Rory Geoghegan, a software developer in the DevOps Team at Behavox. I want to talk about our latest achievement in configuration management, specifically about how we use SaltStack across all our production environments.
How Things Were About Two Years Ago
We have a lot of clients at Behavox, which is a nice problem to have.
As part of our offerings, each customer has their own cluster of machines, which lets us ensure that their data is safely segregated, let them have their own security policies around their cluster, and generally makes them more comfortable with managing their private data.
To update a cluster with our stock SaltStack setup, the members of our SRE team would:
- Schedule a time to ssh into a server
- Run
saltfrom the command line - Sit and wait for the main orchestration to finish
If an error occurred, they would have to scroll through their terminal to try to identify the problem, and have to copy-paste long logs in Slack if they wanted to ask for help from the rest of team.
We have solved a lot of problems relating to deploying to one cluster, but what about updating multiple clusters at the same time? What if we needed to quickly deploy a security fix? What if we wanted more visibility on when and what changes were done, and adding an audit trail to the process? Or monitoring?
Search For a Solution
Our first instinct was to look at some off-the-shelf solutions that built on top of tools we already use.
Ansible AWX
Before migrating to SaltStack, we looked carefully at Ansible AWX, the open-source part of Ansible Tower, as we already had a full Ansible stack working. However, one big problem was that it would use a 'push' instead of a 'pull' model, so if we had any issues with say SSH or networking, we could only know at the last minute, which would stop a deployment in its tracks and cause us maintenance issues.
Also, the open source part (AWX) looked a bit unpolished and the Tower component was very expensive for our use case.
Finally, our clients are located across the globe, and the requirements for Tower would force us to be more geographically restrained than we needed to be.
SaltStack Syndic
We also looked at SaltStack Syndic as a way to coordinate multiple SaltStack masters at the same time. However, in our experience, there were new problems and bugs with this solution on each SaltStack release, and we felt that Salt as a company was directing people to SaltStack Enterprise.
Also, it would have been hard to extend a system built on Syndic to have things like ACLs or auditing.
SaltStack Config
SaltStack Enterprise/SaltStack Config was the natural go to, and we investigated this product heavily. Unfortunately, from how we structure our clusters, the licensing costs would grow too fast for us in the future.
SaltStack was purchased by VMWare around the time of our evaluation, and we figured that their road-map would involve tighter integration with the existing VMWare stack (which we do not use), and less of a focus on stand-alone SaltStack. That was important for us since we are interested in some UI improvements of SaltStack Enterprise and we did not have time to wait.
CCMS
The best option left for us was to build an in-house solution that would satisfy all our requirements. So we set out to build CCMS: The Centralised Cluster Management System.
We already have a full SaltStack system individually running on each cluster, so why not leverage that to manage our deployments? We built a custom SaltStack engine running on the SaltStack master, that would regularly call home for any orchestrations to run, and then a service to route and schedule jobs to specific servers.
The basic topology is to install our custom engine as a plugin on the SaltStack master on each of the clusters to communicate with our CCMS service, and a UI on top for our users to control what happens inside CCMS.
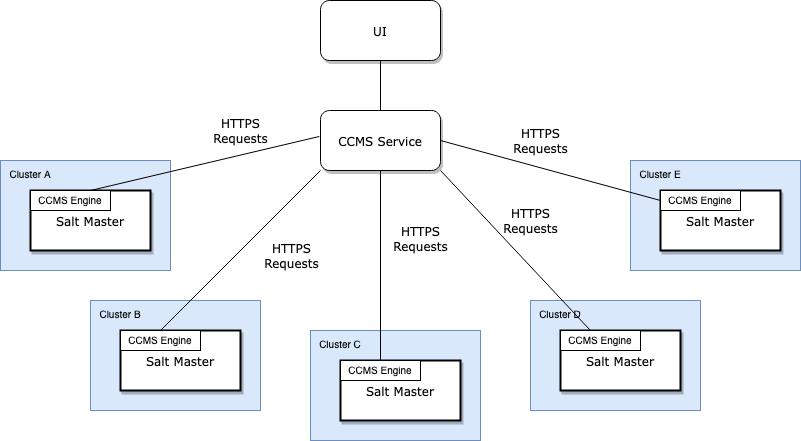
CCMS SaltStack Engine
We designed our custom SaltStack Engine as the simpler part of this whole system. All it is a loop that contacts our CCMS service over HTTPS, authenticates itself, and requests any pending jobs. Once it receives a job, it fires the corresponding SaltStack orchestration off to the SaltStack master, collects the results and returns it to the CCMS service. Since we need to deploy this on our client clusters, and have it running smoothly without too much poking and prodding, it needs to be as simple as possible.
One slight hiccup with this part is how to update the underlying SaltStack state files on each SaltStack master node? Often a job would depend on the latest state files, so we had to find a responsive way to keep them in sync across all our clusters. We figured it would be too error prone to update those with SaltStack itself, (sort of a cutting the tree branch you are sitting on type of situation), so we built a simple script that would query our packaged SaltStack files published by our CI system, update to the latest version of those files, and make SaltStack reload any pillars or states. We, naturally, called this script Resalter.
CCMS Service
This is the more delicate part of the system, as it is a centralised point of failure from both a security and a reliability standpoint.
We divided the service into three parts: a backend responsible for communicating with the SaltStack masters on all our clusters, a frontend offering a web UI so that our users can manage and schedule different jobs, and finally a Postgres database to bridge between the two. We can easily put load balancers in front of the actual servers as all they are designed to share is a database.
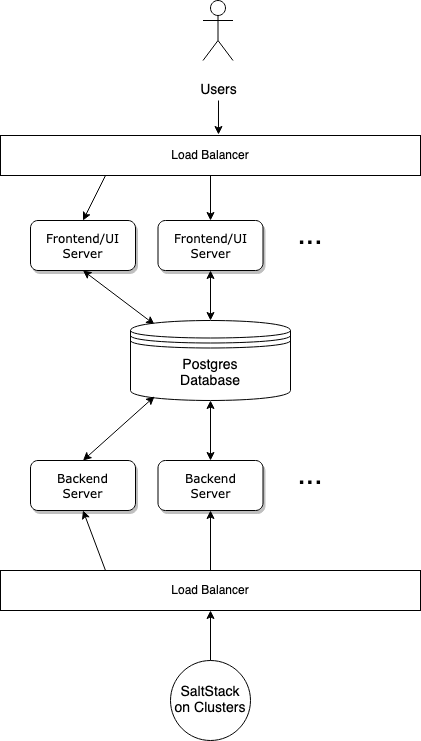
This lets us have a performance focused backend to be available to all our SaltStack masters calling back in, and also provide a feature-rich UI to our users. Also, we decided to use FastAPI and an async Postgres client library, to make sure we can handle as many concurrent SaltStack masters as possible.
CCMS UI
This UI is where we can build complicated rules and policies around our deployments. First of all, all our physical users are authenticated through SSO, and a system of role-based access controls limit specific users to the information and operations they are permitted to do.
We have divided all our clusters by cluster type and function, letting us schedule deploys across whole fleets of clusters or drill down to an individual customer's cluster, as required by our SRE team.
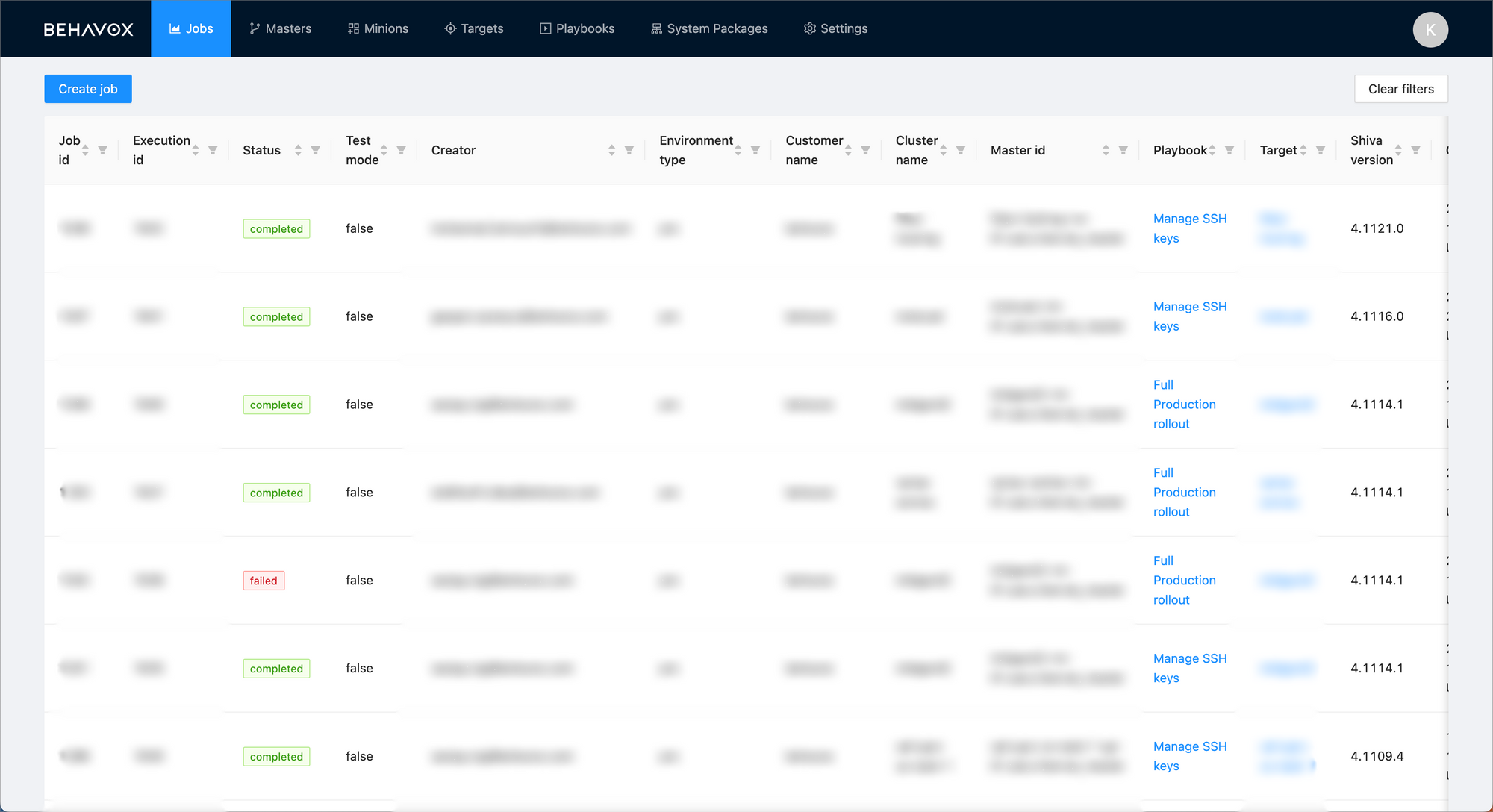
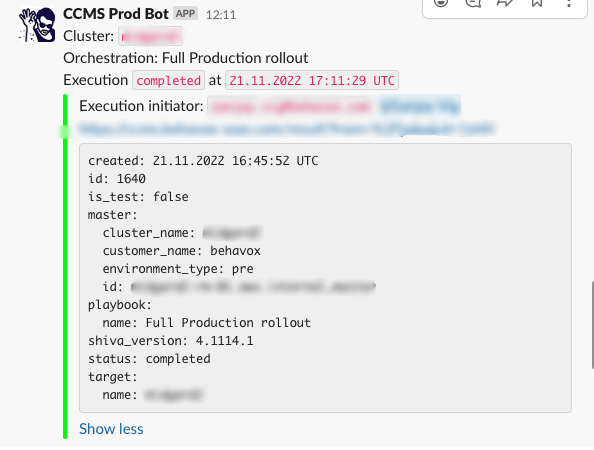
Once run (successfully, or not), the full output of any SaltStack orchestration is transmitted back from the SaltStack master to the UI, showing for any operations the full output from SaltStack which they can debug on their own time or share with a simple url.
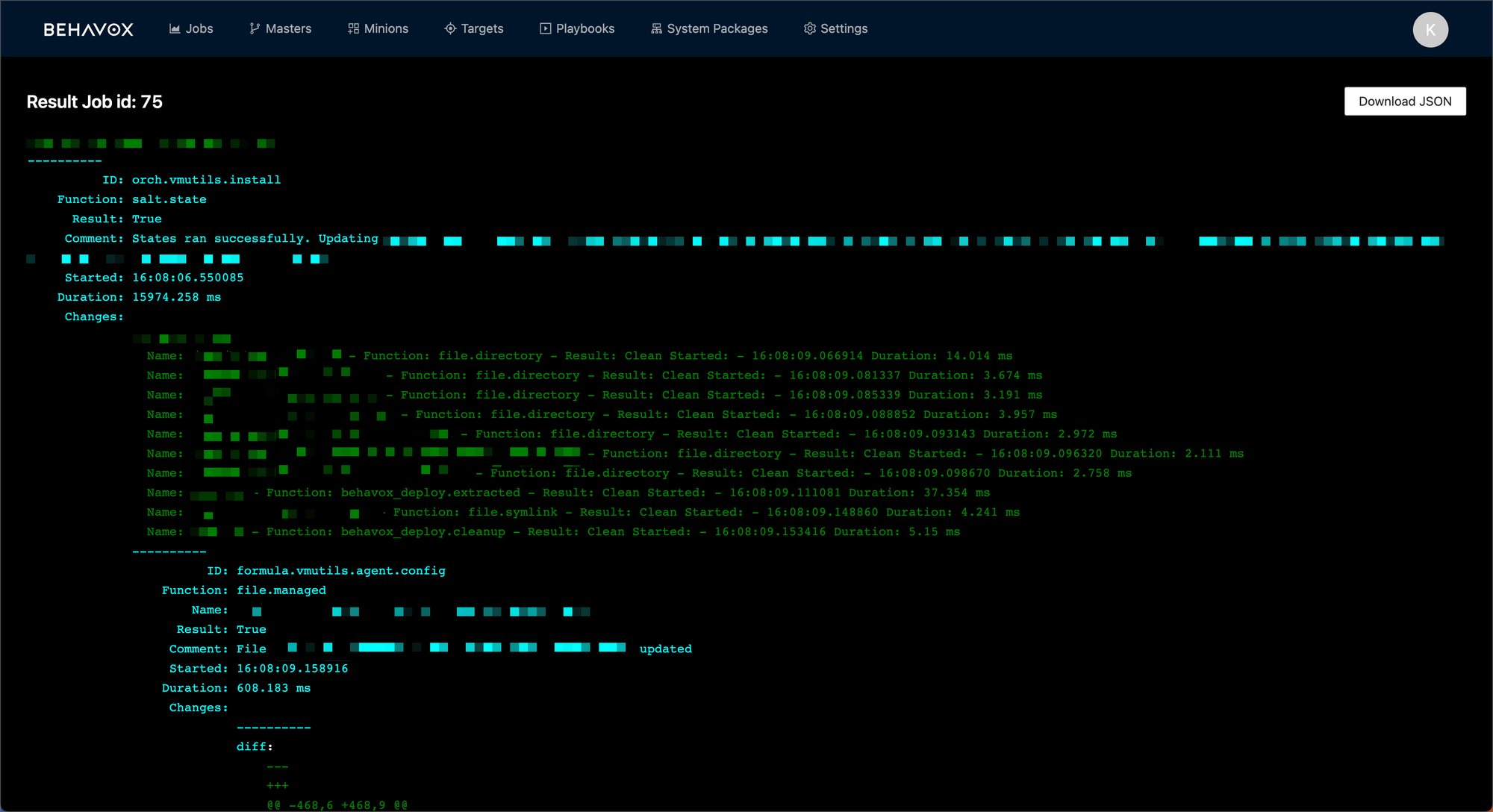
Also, every action, and its response is sent to a Slack channel, so our SRE team can fire off a long-running job, and only need to check Slack to see if it is done.
Security
Security is top of mind for this project, because CCMS, having been designed to provision our clusters, is, by definition, a remote code execution system with elevated privileges. With the help of the Behavox security team, we analysed CCMS and identified a few main threat vectors, and designed mitigations for each one of them.
User Side
Behavox has standardized on Google SSO across the company for user authentication and identification, which lets use enforce things like user onboarding/offboarding, MFA policies, etc. centrally.
We also use a secured HTTPS server to serve the UI, to make sure the user cannot be MiTM attacked. On the app side, we define role-based access controls to limit a specific user from our SRE team to only the clusters and actions that they are responsible for, and to link each action with specific users.
Finally, we feed every action a user commits in the system to a SIEM database, which lets our security team have a live view on what is currently begin done and by whom in CCMS.
SaltStack Master Side
This is where things get a bit trickier, because there are two areas of concern in play here.
The first is where an attacker can mimic a SaltStack master connecting to the CCMS service, whereby they can see what jobs are scheduled for a SaltStack master or affect the responses given back to the service for a specific job. To mitigate this, when a SaltStack master is first run, the CCMS engine communicates with the CCMS service, generates a public-private key pair and sends the public key to the CCMS service (which then saves it in the database). From then on, the SaltStack master uses that private key to authenticate all its communications with the CCMS service. That way, if the CCMS database were to be compromised (like accessing a backup, etc), an attacker would not be able to use the stored public key to get the private key required to sign any incoming messages. This is a lot easier for us to manage at the application layer rather than a scheme like mTLS and have to have a hardened web server (like Nginx) to juggle multiple client certificates.
The second is where a SaltStack master connects to a fake or a Middle-in-the-Middle'd CCMS service, and thereby intercept all the communications between a SaltStack master and the CCMS service. We handle this simply by having a TLS certificate on the CCMS service for which the clients in the CCMS SaltStack Engine can verify the validity.
Chaos Engineering
We at Behavox have invested heavily in chaos engineering to increase the resilience of our systems, give us an idea of current capabilities, and future areas of improvement.
For this project, we were less concerned about the individual SaltStack masters as they are limited by how fast SaltStack can process an orchestration. By design, our CCMS SaltStack engine will only pull and execute one task at a time, so jobs will have to queue up on the server side.
The centralised server is more of a source of concern for us (obviously). The first step was looking at resilience by starting to pull on different strands in the system, like cutting database access, etc. This is very important, even if it did find some bugs that we fixed, but more because it lets us at least know about the weaknesses and limits of the system, and move from "here be dragons", to "don't do that, because it will cause X, Y, Z and the service will be unavailable for XX time".
The second part is load testing the system. What we did is we designed a python script that could mimic the interactions of the CCMS SaltStack engine with CCMS, following the authentication schema detailed in the Security section above. From there, we just hammered our CCMS service to perform both stress tests to emulate heavy load over a short period of time, and endurance tests where we put a lighter load but over a much longer time (24, 36 hours). Our load testing confirmed a minimum "performance envelope" of 100 SaltStack masters each with 1000 SaltStack minions, and to know what is a normal load, and a high load which could cause service degradation, which should give us a few years of headway.
Conclusion
Overall, CCMS has been a very fun project at Behavox, with a quick return on our investments. With CCMS, we deploy a minor configuration change across all our clusters in less than 5 minutes, where before it would have taken the team the better part of a day to do it over the command-line with Ansible.
CCMS is a major step in reducing our SRE team's toil, which a) makes them happier, and b) lets them focus on solving systemic problems with the systems instead of getting distracted with business-as-usual tasks.
Also, having a stable connection to the SaltStack master on all our clusters lets us collect a lot of information about our clusters. For example, we have already integrated the output from SaltStack grains for all our minions with our security team, and have an automated up-to-date report of all outdated or vulnerable packages on every server on our clusters.