Configuration Management in Behavox: Part 2 - SaltStack


Hey, it's Kirill Proskurin, Head of DevOps Engineering at Behavox.
In Part 1, I talked about Behavox's experience with Ansible. The conclusion was that while Ansible is a good tool for what it does, we wanted something more scalable.
It was 2018 and we looked into what DevOps configuration management tools were available on the market. We evaluated Puppet and Chef, but they didn't solve our scalability issue. Each option had disadvantages of their own, like orchestration being locked behind a paywall in Puppet. Also, we had way more Python expertise than Ruby.
There were several lesser-known tools available, but we had the impression that they were not mature enough.
This eventually led us to our final candidate, SaltStack.
No one on the team had any experience with SaltStack, but its feature list was very intriguing:
- Supports multiple configurations like Master-Minion, Masterless, Multimaster, Master of Masters, and Masterless via ssh.
- Master-Minion configuration uses a ZeroMQ or raw TCP transports.
- Can do complex orchestration, ad-hoc executions, scheduled executions, and event-based executions.
- Executions can be called via CLI or via HTTP API
- Has Auth and Authz
- Written in Python
- Free and Open (Apache 2.0 license) with a big and active community
And the most important feature:
In SaltStack, speed isn’t a byproduct, it is a design goal
Too good to be true, right?
Architecture
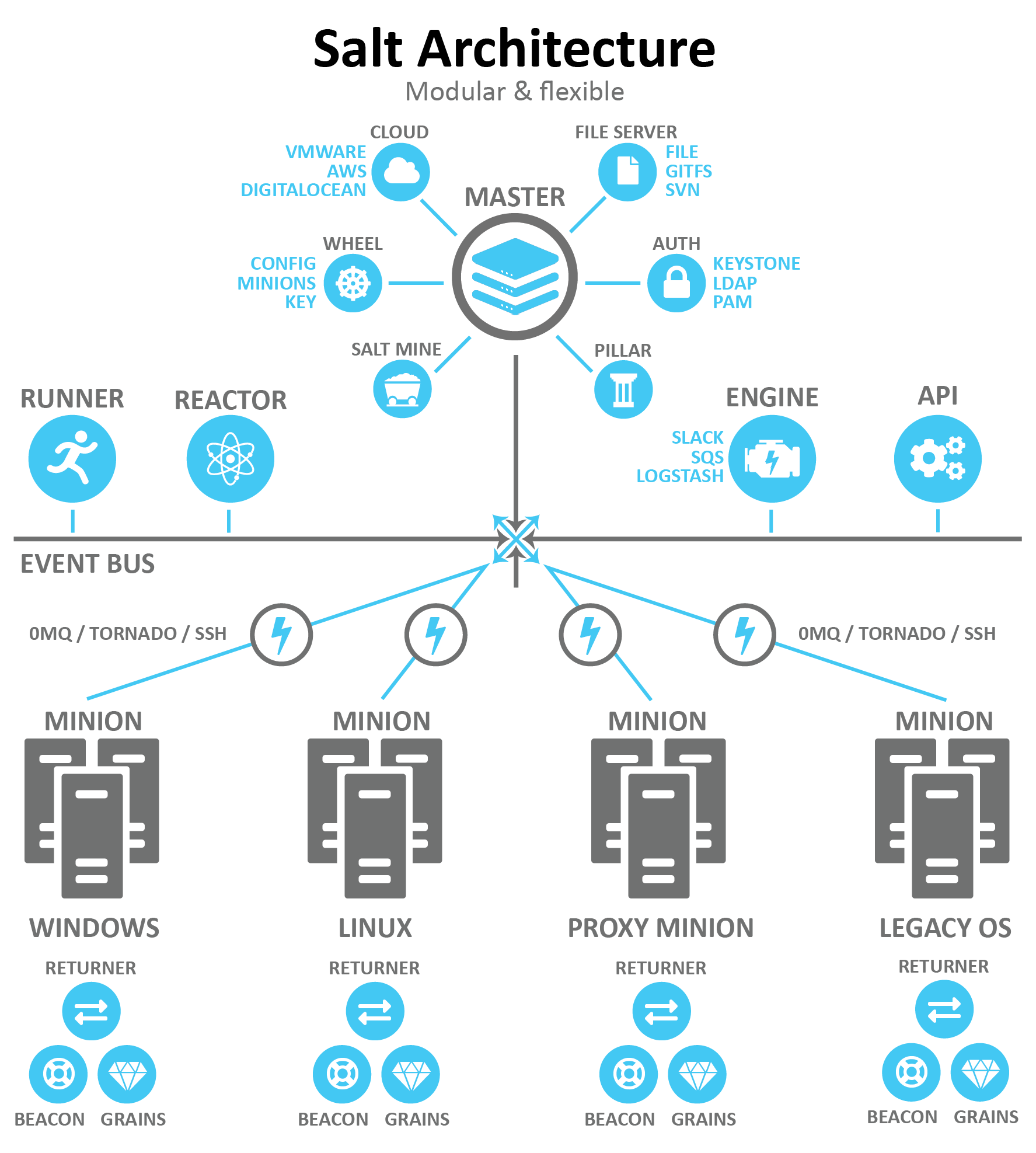
The SaltStack feature list is so vast - it's pointless to describe here in full. The good news is that you can use only those features that are part of your solution. For example, we're aware of SaltStack SSH but don't need it in our solution.
Here are several excellent resources for more information on SaltStack: Overview, Tutorial, and SaltStack deconstruction video by Carson Anderson.
SaltStack evaluation
At the end of 2018, we started a PoC to evaluate SaltStack. We wrote the SaltStack deployment logic using Ansible, which was a bit funny but worked quite well for us. We migrated a small subset of Ansible roles just to check how it would look like with our real logic.
Deployment was straightforward even though we had to do it slightly different because of security reasons. The logic worked and produced the same results as the Ansible counterpart. We managed to reuse our existing test suite to test SaltStack. But we had problems as well.
First of all, we found bugs and quite a lot of them. To be fair, Ansible is buggy as well and any configuration management tools would probably share the same issues because of their vast surface. I'll talk about bug fixing, debugging, and extending SaltStack later.
Secondly, we realized quite early that there was no one right way of doing things in SaltStack. This is usually the case with configuration management tools, but with SaltStack, it was taken to the extreme. SaltStack's main strength is also its main weakness - it does way too much.
As I searched the SaltConf archives for the code structure of the official formulas (SaltStack's name for "roles" in Ansible terminology), I gradually started to write a Behavox SaltStack best practices style guide.
Thirdly, we realized that the default system to keep data\variables in SaltStack, called Pillars, had its limitations and was not suited for use with our variables hierarchy.
The good news is that SaltStack is extremely extendable and we just switched to the third-party Pillars implementation, called PillarStack, which is more or less the same as Puppet's hiera.
Pillars also lacks Ansible's variables lazy interpolation feature which was partially mitigated by the PillarStack stack dict functionality. While it was a regression, we agreed that lazy interpolation leads to overcomplicated data structures and coupling of roles. And one of the goals of the SaltStack migration was to decouple everything and simplify variables, so we agreed that it was not such a bad thing for us.
Finally, we realized that SaltStack had a steep learning curve as compared to Ansible. In my personal experience, I needed about a week to learn how to work with Ansible, and about a month to learn some advanced tricks.
With SaltStack, without any guidance, I needed about one to two months to comfortably start to work with it. As for learning advanced tricks, the sky is the limit. I still occasionally learn something new about SaltStack even after working with it for three years.
SaltStack DSL
It would be misleading to call SaltStack DSL as YAML-based. While this is true for the default configuration, as with many things in SaltStack, it's up to you.
SaltStack has the concept of Renderers. The default one is defined as jinja|yaml and that means that SaltStack SLS files will be rendered first via Jinja and later via YAML. So you could do things like this:
{% if grains['os'] != 'FreeBSD' %}
install_web_packages:
pkg.installed:
- pkgs:
- nginx
- apache
{% endif %}
create_motd:
file.managed:
{% if grains['os'] == 'FreeBSD' %}
- name: /etc/motd
{% elif grains['os'] == 'Debian' %}
- name: /etc/motd.tail
{% endif %}
- source: salt://motdAs you can see, you have the full power of Jinja here, not the subset\special cases like in Ansible, but anything that Jinja provides.
But SaltStack doesn't stop here. Do you want to do a jinja|mako|yaml? You can:
#!jinja|mako|yaml
An_Example:
cmd.run:
- name: |
echo "Using Salt ${grains['saltversion']}" \
"from path {{grains['saltpath']}}."
- cwd: /
<%doc> ${...} is Mako's notation, and so is this comment. </%doc>
{# Similarly, {{...}} is Jinja's notation, and so is this comment. #}Decrypt armored GPG secrets first? Sure. Hjson? Go ahead.
You can use numerous available renderers or write your own. You can even have a pure python renderer - Hello Chef!
#!py
def run():
config = {}
if __grains__['os'] == 'Ubuntu':
user = 'ubuntu'
group = 'ubuntu'
home = '/home/{0}'.format(user)
else:
user = 'root'
group = 'root'
home = '/root/'
config['s3cmd'] = {
'pkg': [
'installed',
{'name': 's3cmd'},
],
}
config[home + '/.s3cfg'] = {
'file.managed': [
{'source': 'salt://s3cfg/templates/s3cfg'},
{'template': 'jinja'},
{'user': user},
{'group': group},
{'mode': 600},
{'context': {
'aws_key': __pillar__['AWS_ACCESS_KEY_ID'],
'aws_secret_key': __pillar__['AWS_SECRET_ACCESS_KEY'],
},
},
],
}
return configIn the end, it's what SaltStack is expecting: a Python dictionary with a specific format.
The downside of such DSL is that writing a linting tool for it is close to impossible. Even if you'd focus on some strict subset of renderers like Jinja + YAML, you still need to render Jinja first to validate the YAML, and sometimes it's impossible to do so outside of the real environment since you may need environment-specific variables for rendering.
Declarative? Idempotent?
SaltStack makes it very clear what is expected to be declarative and idempotent and what is not.
SaltStack splits its logic into three categories:
- Utils
- Modules
- States
Utils contain some shared code that is expected to be reused in Modules. Utils are not going to be executed on their own.
Modules are not declarative and not idempotent verb-like pieces of logic like "create file", or "execute MySQL query", and so on. Modules are mostly used by States but they could be used on their own for some ad-hoc executions.
States are declarative and idempotent pieces of logic and the main working instrument that you're going to use. Inside it's just a chain of modules executed and with some pre- and post-checks to make the result idempotent.
I think it's a very clear and good structure.
Debugging and extending SaltStack
Writing new utils, modules and states are incredibly easy. For utils and modules, you don't need to follow any SaltStack-specific rules, just write your logic.
For states, the only thing that is required from SaltStack is that the return data must be a Python dict containing a few keys: "name", "comment", "changes", and "result". That's it.
You can and should write or reuse some modules that will do the work and add some logic to check the results before and post the execution to identify if the change is needed, and if it was needed, what was the change result.
And in the majority of cases, SaltStack already has needed logic written as a module so all you need to do is to chain multiple modules and utils inside the state and add idempotency checks.
After the code is written, you need to drop it into a special directory in your SaltStack deployment and run a sync_all command. Your code will then be distributed to all minions and it's ready to be used.
So how can we debug our code? The easiest way is to usually add logging. You can execute your state or module with any logging level and see all the output.
So all you need is to:
- Modify the code
salt '*' saltutil.sync_allsalt-call <your_module> -l debug
You can make it as verbose as you like, with different logging levels, similar to any other Python application.
Also, SaltStack is very extendable beyond just updating the modules and states. You could modify:
Click to expand
- beacons
- clouds
- engines
- grains
- log_handlers
- matchers
- modules
- output
- proxymodules
- renderers
- returners
- sdb
- serializers
- states
- thorium
- utils
- pillar
This is seriously impressive!
Scalability and Performance
We found that many things could affect scalability and performance and it's quite easy to slow down SaltStack if you don't know what you're doing.
The first performance killer is the generation of Pillars.
In the majority of cases, SaltStack Pillars won't be updated unless you tell SaltStack Master to refresh them, because it's a very CPU-heavy operation and it's executed on Master for security reasons.
The original idea behind Pillars is to keep mainly sensitive information in them, that is why only the Master has control over them and only the Master decides which Minion will receive which Pillar.
Partially due to that Pillars are generated for each minion individually, meaning if you have 1000 minions, SaltStack Master has to generate it 1000 times. Performance-wise, this is far from optimal.
So the first thing to check is to reduce Pillars to the absolute minimum and don't do any "smart" things inside them. SaltStack will allow any Jinja execution inside Pillars and it won't stop you if you decide to call some external database or SaltStack itself inside Pillars.
To make matters worse, SaltStack sometimes decides to regenerate Pillars without operators' direct request, for example during highstate execution. And I think you can't disable that, so you may run into a situation where Pillars are refreshed multiple times even if you don't want them to.
You can and probably should cache Pillars but now you have to think about dropping cache at the right moment and some security risk of keeping it on disk.
The second performance and scalability killer is Minions data return.
SaltStack is very scalable due to its ZeroMQ transport on publishing execution commands, but after those commands are finished running, Minions have to connect back to Master and send the results. If 1000 minions decide to connect to Master at the same time, they could easily overload it.
As a workaround, you can and should do execution in batches and set reasonable worker threads Master parameter. Also, make sure your SaltMaster node has enough CPU resources to handle those workers. The reasonable worker_threads value would be cpu_count * 1.5, but you have to check and test to see what works best for your setup.
You can also increase the timeout and gather_job_timeout parameters to help mitigate some of the load spikes.
Migration
By the beginning of 2021, we agreed that SaltStack was the best option available for us and began the migration.
We had 100+ Ansible roles to migrate, some of which were very big and complex, and we couldn't freeze the rollouts and had to support routine operations like adding new features to the existing logic.
We had to switch the plane's engine in-flight, so to say. And we had to be very conservative regarding the possible work capacity for that activity to avoid sabotaging "business as usual".
We estimated that the migration would take around a year, but it took two years.
First of all, we agreed to add all of the new logic in SaltStack. Also, we agreed to reuse our available test suite so we could be more confident about not breaking something and missing anything by introducing new tests. I'll tell you about the Behavox infrastructure and deployment testing in future blog posts.
We also realized that we would have two sources of truth: Ansible and SaltStack. No matter how we ordered the migration, some of the logic would remain in Ansible, but SaltStack had to be aware of it. For example, the topology configuration of the racks for rack-aware databases and so on.
We could have duplicated that information but this would have resulted in a misconfiguration, or we could have passed the variables from Ansible to SaltStack. We chose the latter.
Since we used Ansible to deploy SaltStack, we realized that we could template an additional file that we called infra-vars via Ansible and read it by PillarStack and reuse that infrastructure information later.
We started migration from the bottom of the Behavox tech stack since moving higher up the stack would have required more dependencies and interconnections on the deployment logic. So in the beginning, we migrated OS-related things, then databases, then some infrastructure services, and finally the product.
The complexity of the migration increased as we moved higher up the stack. We also had to untie multiple "migration deadlock" situations and coordinate a lot with our SRE team along the way.
On the bright side, we used this opportunity to rethink multiple older decisions, burn some of the tech debt, and introduce multiple simplifications and decoupling.
We also switched to a deep merge approach to the variables that we avoided in Ansible.
It's not often you have a chance like this.
Conclusions
We are now in 2022 and finished the migration a few months ago. We underestimated the complexity and time that we'd need to do the migration, but on the other hand, we didn't have a single major incident along the way. Sometimes taking it slow is a good idea.
Our recommendation is to do it evolutionary, not revolutionary. If your system is anything but simple, you usually won't be able to put it on hold or implement a new one in parallel.
There is a great pattern in Software Engineering called branch by abstraction. We followed something similar during this migration, like keeping both logic at the same time with the same tests and monitoring and switching from one to the other when the time comes.
By migrating to SaltStack, we reached the expected scalability and rethought and improved many things along our journey.
It also opened the possibility of adding a Centralized Deployment System, but this will be discussed in the next blog in this series. So stay tuned!