Configuration Management in Behavox: Part 1 - Ansible


Hey, it's Kirill Proskurin, Head of DevOps Engineering at Behavox.
Five years ago when I joined Behavox, Ansible was all the rage. It promised a very easy to use and powerful configuration management tool, and it didn't come as a surprise that Behavox already used it.
In fact, Behavox was very invested in it - we used it for cloud provisioning, configuration management, and as a deployment tool.
To be fair, it was more than enough for the Behavox scale of that time. I'd even argue that it was more than adequate for cloud provisioning since Terraform didn't even have a "for loops" at the time. We're going to talk about cloud provisioning later, so let's get back to configuration management.
Let's talk about some of the biggest challenges and our overall experience with Ansible.
Variables hierarchy
Like most companies, Behavox has separated Dev, Staging (we call it "pre"), and Production environments. So naturally, we wanted to separate the custom configuration of each while keeping common elements. We also wanted to have customer-wide, cluster-wide, and node-wide overrides.
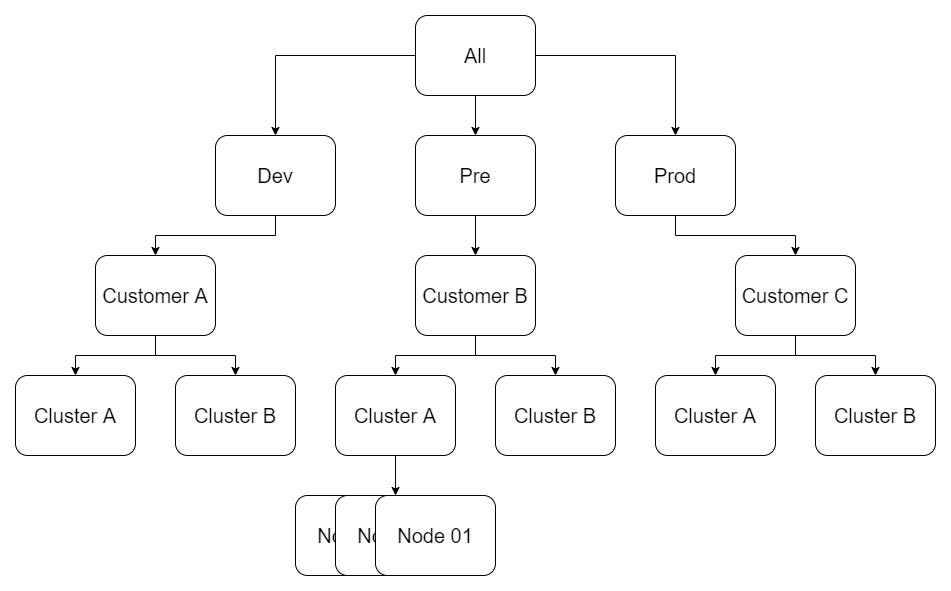
I joined with multiple years of Puppet experience, and I really loved the concept of the hiera and achieving that configuration hierarchy would be relatively simple with it.
While hiera lookup was available for Ansible, we considered it a bit alien at the time and decided to go with the Ansible-native approach.
To this day, I think this is a poorly documented part of Ansible. I scoured Ansible documentation, and unless I missed something, Ansible variables structure is not clearly explained. Yes, there are this and this and that but I'm struggling to find the exact example of how we did our structure so let me just explain it here.
We agreed to set variables in three places:
- Inventory: for topology-related variables
- host_vars: for host-specific variables
- group_vars: for everything else
Our group_vars looks like this:
group_vars/all/
group_vars/{dev,pre,prod}/
group_vars/{dev,pre,prod}_CUSTOMER/
group_vars/{dev,pre,prod}_CUSTOMER_CLUSTER/So, for example: group_vars/prod_behavox_monitoring/
And the idea that we going to inherit and override all variables in that order:
inventory -> all -> prod -> behavox -> monitoring -> host
And for that to work we need to have inventory groups like this:
[cluster]
<all nodes here>
[some_other groups]
[prod_behavox_monitoring:children]
cluster
[prod_behavox:children]
prod_behavox_monitoring
[prod:children]
prod_behavoxIt's a bit confusing, and I'm struggling to link the related documentation but it actually works pretty well for us. So even though it's not as clean as it would be in hiera I think we managed to solve the hierarchy of the variables in Ansible.
Debugging, extending, and working with Ansible
Ansible has simple and clean yaml-based DSL. It's mostly easy to read and understand. My pet peeve is the need to add double quotes to keys with jinja variables but we can live with that.
Ansible has a very powerful conception of when + register that would allow chaining multiple tasks into a seamless logic. The downside of that is the rise of a code style called "bashsible", when Ansible is used like a glorified bash script.
- name: Check if mysql is running
command: "mysql -u root -p{{ mysql_root_pass }} -Nse 'select 1'"
register: mysql_status
changed_when: false
failed_when: false
check_mode: false
- name: Set facts - mysql_running
set_fact:
mysql_running: "{{ true if mysql_status.rc == 0 else false }}"
We think it's fine for some cases but overall it's a problem. To a man with a hammer, everything looks like a nail.
It's fair to say that Ansible's when + register + delegate_to allows running a very powerful orchestration logic. Also, Ansible has a powerful variables lazy interpolation feature, meaning you could do this in a single file:
root_dir: /opt/some_dir
app_home: {{ root_dir }}/appIt's very powerful, but uncontrolled it could lead to very complex variable structures. Also, it's very slow.
It's also not that easy to call Ansible a declarative system. While some Ansible modules are declarative, some aren't.
The same thing with idempotency, outside of multiple idempotency bugs some of the Ansible modules are not idempotent by design and Ansible adds some additional instruments to hack idempotency into it, like the changed_when parameter.
Extending Ansible is relatively easy, write a module, drop it in your plugins directory and use it. But that leads us to debug, and it is not very good.
First of all, the Ansible module can only return a single object. It won't produce any logs or any other additional context. To debug it you need to do the following:
- Execute the Ansible playbook with ANSIBLE_KEEP_REMOTE_FILES=1
- Check the execution output for temp path with Ansible files
- ssh into remote host and cd into temp directory
- Unpack the module
- Modify the module to have some debug information like logs or print(the majority of modules don't have any)
- Execute and repeat the previous step until the root cause of the problem is found
I can't say that we find this approach easy and convenient.
Scalability
Around the end of 2018, we were asked if we could do a 1000 nodes cluster deployment, three times per day.
It is worth setting some context here. Deployment in Behavox historically took some time. Many things have changed, but in 2018 each deployment looked like this:
- Setting the monitoring maintenance
- Creating the databases snapshot
- Running Ansible in batches of 50 that would download needed artifacts, change the configuration and restart the applications if needed.
We had around 100 Ansible roles at the time, each representing a separate application or system. We also had and still have an approach of deployment logic being written in a "fire and forget" way. Meaning no manual operations are allowed, and all migrations and complex orchestrations must be automated.
On top of 100 roles, we needed to execute all those migrations and additional logic as well. And all that adds up to the overall deployment time. But why it's slow?
Let's talk about Ansible internals and transport.
Ansible in a nutshell is a glorified ssh loop. When you launch an Ansible playbook you start a Python application that copies some other Python scripts to target hosts, executes them, and copies the output of the execution back. That's it.
This is a simple approach and it has a lot of limitations. This is what typical Ansible execution looks like:
ssh -o ForwardAgent=yes -o ControlMaster=auto -o ControlPersist=600s -o StrictHostKeyChecking=no -o Port=22 -o 'IdentityFile="/tmp/elasticsearch-salt-withmaster-current/ssh_key"' -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o User=someuser -o ConnectTimeout=10 -o UserKnownHostsFile=/dev/null -o ControlMaster=auto -o ControlPersist=60s -o IdentitiesOnly=yes -o StrictHostKeyChecking=no -o ControlPath=/home/REDACTED/.ansible/cp/%h-%p-%r 172.31.23.3 '/bin/sh -c '"'"'sudo -H -S -n -u root /bin/sh -c '"'"'"'"'"'"'"'"'echo BECOME-SUCCESS-lpecwxhszeyfmvzzvfgbqaxgyctivtwe; PATH='"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'/opt/behavox/.local/bin:/opt/behavox/scripts/bin:/opt/behavox/mysql/current/bin:/opt/behavox/java/current/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin:$PATH'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"'"' /usr/bin/env python'"'"'"'"'"'"'"'"' && sleep 0'"'"''
scp -o ForwardAgent=yes -o ControlMaster=auto -o ControlPersist=600s -o StrictHostKeyChecking=no -o Port=22 -o 'IdentityFile="/tmp/elasticsearch-salt-withmaster-current/ssh_key"' -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o User=someuser -o ConnectTimeout=10 -o UserKnownHostsFile=/dev/null -o ControlMaster=auto -o ControlPersist=60s -o IdentitiesOnly=yes -o StrictHostKeyChecking=no -o ControlPath=/home/REDACTED/.ansible/cp/%h-%p-%r /ws/roles/common_user_env/files/screenrc '[172.31.18.215]:/opt/behavox/.ansible/tmp/ansible-tmp-1573069165.36-50102547946249/source'
It's not made up, it's a real command and Ansible executes hundreds of those for each run. So for each Ansible task, it has to do the following and note that each step is a separate connection:
- Check the connectivity and escalation to the remote host
- Copy all needed scripts and templates and everything else needed to the remote host temp directory
- Execute the script and save the output
- Remove temp dir
- Send output back to the controller node
The main benefit of this approach is an "agentless architecture". All you need to run Ansible is an SSH connection, which is one of the main selling point of Ansible. Plus it comes with almost zero configuration required since SSH is usually already available and ready to work.
RedHat calls that "radically simple automation" and I agree, but the cost of that is scalability issues. Ansible is agentless so if you have a 1000 nodes cluster, 100 roles with, let's say, 20 tasks in each, Ansible will need to do 1000 * 100 * 20 * 5 network calls. Even in check mode. That is a lot.
And don't forget that we need to limit the batch size to something like 50 unless you want to use a very beefy Ansible controller node. And that Ansible needs to pack and unpack the logic and the data that it sends to the remote node, and that it needs to run the Python interpreter each time.
We tried everything that we could to speed up things:
- Pipelining
- Smart facts gathering and disabling or limiting of facts gathering when it's not needed.
- Playbooks and roles restructure, like merging some tasks(yum calls, etc)
- Using more loops since it's more efficient connectivity-wise
- Some ssh commands optimizations
- Checked the Mitogen plugin but considered it too experimental and not widely supported
So, we tried everything that Ansible proposed - except tags and free strategy since they go against our deployment approach.
After all those experiments we finally agreed that Ansible can't scale to our expectations.
Conclusions
Ansible is a great tool for small to medium-sized deployments. I'd say up to 100 nodes. It's easy to use and with some style enforcement and discipline, it could serve you well.
For us, scalability was the tipping point so we decided we need to switch to something else.
So what did we choose? Check Part 2 of that article!